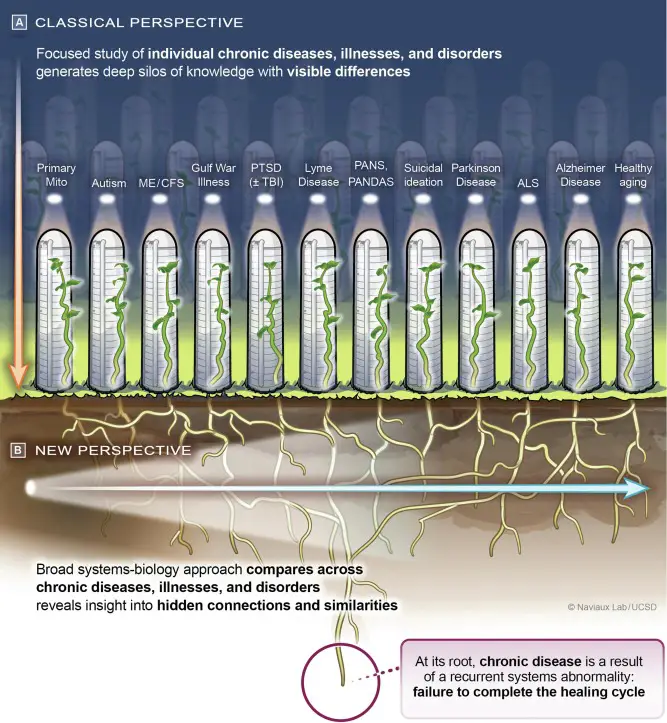
Causality in machine learning is the study of cause and effect relationships in data. This article provides a comprehensive introduction to the concept and its applications in machine learning.
Causal relationships play a fundamental role in understanding and predicting outcomes in various domains. In machine learning, causality helps identify the underlying mechanisms driving data patterns and enables the development of more accurate predictive models. By establishing causal relationships, we can move beyond correlations and uncover the true effects of variables, allowing for more informed decision-making.
This article will explore the key concepts of causality in machine learning, including causal inference, causal models, and different methods used to identify causal relationships. We will also discuss the challenges and limitations of causal analysis in machine learning and highlight its importance in various real-world applications. By the end, you’ll have a solid understanding of how causality can enhance your machine learning algorithms and lead to more impactful insights.
Credit: www.mdpi.com
Understanding The Importance Of Causality In Machine Learning
The Significance Of Causality In Machine Learning
In the world of machine learning, causality plays a crucial role in understanding and interpreting data. While correlation may provide insights into patterns and relationships between variables, causality goes a step further by identifying the cause-and-effect relationships between those variables.
This distinction is vital not only for accurately predicting outcomes but also for making informed and effective decisions based on those predictions.
Here are the key points to understand the significance of causality in machine learning:
- Causality helps us uncover the true reasons behind observed patterns: By focusing on causality, we can identify the factors that directly influence a given outcome. This deeper understanding allows us to go beyond surface-level correlations and uncover the underlying causes driving those correlations.
- Causal reasoning enables us to make more accurate predictions: When we know the causal relationships between variables, we can make more accurate predictions about how changes in one variable will impact another. This predictive power can be especially valuable in various fields such as healthcare, finance, and marketing, where accurate forecasts can drive strategic decision-making.
- Causal analysis aids in counterfactual reasoning: Causal analysis enables us to explore counterfactual scenarios, where we can understand how outcomes would have changed if certain variables had been different. By studying counterfactuals, we can gain insights into the potential impact of interventions or policy changes, helping us make evidence-based decisions.
- Causality promotes fairness and accountability in decision-making: Understanding causality allows us to evaluate the impact of decisions or policies on different groups of individuals. By considering causal effects, we can uncover potential biases and work towards designing fairer and more equitable systems.
By recognizing the importance of causality in machine learning, we can move beyond merely identifying correlations to understanding the underlying mechanisms that drive those correlations. This deeper understanding empowers us to make more accurate predictions, explore counterfactual scenarios, and design fairer decision-making processes.
Causality truly serves as a foundation for unlocking the full potential of machine learning in various domains.
The Basics Of Causal Inference
Causal inference is a fundamental concept in machine learning that aims to understand cause and effect relationships in data. By identifying causal relationships, we can uncover insights and make predictions about how changes to one variable will impact another. Let’s delve into the basics of causal inference and explore the key concepts that underpin this field.
Defining Causal Inference And Its Purpose In Machine Learning
- Causal inference is the process of determining the cause-effect relationship between variables.
- Its purpose in machine learning is to understand how changes in one variable affect other variables, enabling better decision-making and prediction.
Key Concepts In Causal Inference, Such As Confounding And Counterfactuals
Confounding:
- Confounding occurs when an additional, unmeasured variable influences both the cause and effect, leading to spurious correlations.
- It is important to identify and control for confounding variables to accurately determine causal relationships.
Counterfactuals:
- Counterfactuals refer to the unobserved outcomes that would have occurred if a different causal intervention had taken place.
- By comparing observed outcomes with counterfactuals, we can infer causal relationships and assess the impact of interventions.
The Role Of Causal Graphs In Representing Causal Relationships
- Causal graphs, also known as causal diagrams or directed acyclic graphs (dags), visually represent the causal relationships between variables.
- Using directed edges, the graph shows the direction of causation, allowing us to determine which variables influence others.
- Causal graphs help us identify confounding variables and determine the necessary variables to adjust for to estimate causal effects accurately.
Causal inference plays a crucial role in machine learning by enabling us to uncover the cause and effect relationships in data. By understanding key concepts such as confounding and counterfactuals, we can make accurate predictions and inform decision-making. Causal graphs provide a visual representation of these causal relationships, aiding in the identification of confounding variables and improving causal effect estimation.
By leveraging the power of causal inference, we can unlock deeper insights and improve the efficacy of machine learning models.
Methods And Techniques For Establishing Causal Relationships
Machine learning algorithms have made significant strides in recent years, enabling us to uncover valuable insights and make predictions based on complex data sets. However, while correlation is often used to infer causation, establishing causal relationships requires a more rigorous approach.
In this section, we will explore several methods and techniques for establishing causal relationships in machine learning. By understanding and implementing these techniques, we can ensure that our models accurately capture the true cause and effect relationships within our data.
Experimental Design And Randomized Controlled Trials
Experimental design and randomized controlled trials (rcts) are widely recognized as the gold standard for establishing causality in scientific research. In the context of machine learning, rcts involve randomly assigning participants to different treatment groups and measuring the effects of the treatments on the outcome of interest.
Here are some key points to consider:
- Rcts allow for the control of confounding variables, ensuring that the treatment effect is isolated.
- Random assignment helps to eliminate selection bias, ensuring that treatment groups are comparable.
- Rcts provide a clear temporal order between the treatment and outcome, establishing causality.
Propensity Score Matching And Regression Adjustment
Propensity score matching and regression adjustment are techniques commonly used when conducting observational studies, where random assignment is not possible. These methods aim to reduce the effects of confounding variables and approximate the conditions of a randomized controlled trial. Consider the following points:
- Propensity score matching involves identifying individuals with similar propensity scores (probability of receiving treatment) and comparing outcomes between treated and control groups.
- Regression adjustment uses statistical models to estimate the causal effect by accounting for the influence of confounding variables.
- Both techniques aim to minimize bias and increase the comparability between treatment and control groups.
Instrumental Variables And Natural Experiments
Instrumental variables and natural experiments offer alternative approaches for establishing causal relationships when rcts are not feasible. These methods leverage unique circumstances or external factors that mimic the random assignment of treatments. Here’s what you need to know:
- Instrumental variables are variables that are correlated with the treatment but have no direct effect on the outcome. They can be used to estimate the causal effect of the treatment.
- Natural experiments occur when external factors or events create quasi-experimental conditions, allowing researchers to identify causal relationships.
- These techniques rely on assumptions and careful identification of valid instruments or natural experiments.
By employing these methods and techniques, machine learning practitioners can go beyond simple correlations and unlock the true causal relationships within their data. Whether through experimental design, matching and adjustment, or instrumental variables and natural experiments, understanding causality is crucial for building robust and trustworthy machine learning models.
Applications Of Causal Inference In Machine Learning
Causal inference, a branch of statistics and machine learning, plays a crucial role in various applications, enabling us to understand cause-and-effect relationships between different variables. By examining complex datasets, evaluating interventions and policies, and analyzing outcomes, causal inference empowers us to make informed decisions.
Let’s explore some key applications of causal inference in machine learning.
Causal Discovery And Exploration In Complex Datasets:
- Causal inference allows researchers to discover and explore causal relationships within complex datasets, helping uncover hidden insights and patterns.
- By utilizing methods such as graphical models and bayesian networks, causal discovery techniques can identify causal structures and direct dependencies between variables.
- Insightful causal exploration can lead to better understanding of the underlying mechanisms and contribute to the development of more accurate predictive models.
Causal Inference In Evaluating Interventions And Policy Decisions:
- Causal inference is essential for evaluating the effectiveness of interventions and policy decisions in various domains, such as healthcare, economics, and social sciences.
- Through the use of randomized controlled trials (rcts) and quasi-experimental designs, causal inference measures the causal impact of interventions by comparing outcomes between treatment and control groups.
- This application of causal inference helps policymakers make data-driven decisions and assess the potential outcomes of different interventions before implementation.
Causal Inference In Predictive Modeling And Outcome Analysis:
- In predictive modeling, causal inference enhances the accuracy and interpretability of machine learning models by accounting for causal relationships between input features and the predicted outcome.
- Causal inference helps in avoiding spurious correlations and tackling confounding factors that may lead to erroneous predictions.
- By leveraging methods such as propensity score matching or instrumental variable analysis, causal inference enables us to estimate the causal effect of specific features on the prediction outcome.
Causal inference in machine learning has far-reaching applications, from uncovering complex causal structures within datasets to evaluating interventions and improving predictive models. By harnessing causal relationships, we gain deeper insights into cause-and-effect dynamics, leading to more informed decision-making and better outcomes in various domains.
Frequently Asked Questions For An Introduction To Causality In Machine Learning
Faq 1: What Is Causality In Machine Learning?
Causality in machine learning studies the cause-and-effect relationships between variables, enabling us to understand how one variable influences another.
Faq 2: Why Is Causality Important In Machine Learning?
Causality is crucial in machine learning as it helps us uncover the underlying mechanisms of data and make accurate predictions that can drive informed decision-making.
Faq 3: How Does Causality Differ From Correlation In Machine Learning?
While correlation indicates a relationship between variables, causality goes a step further by determining the cause-and-effect relationship, ensuring more reliable and actionable insights.
Faq 4: What Are The Challenges Of Inferring Causality In Machine Learning?
Inferring causality in machine learning can be challenging due to confounding variables, limited data availability, and the need for defining causal models and assumptions accurately.
Faq 5: How Can We Apply Causality In Real-World Machine Learning Scenarios?
Causality in machine learning finds applications in a range of fields like healthcare, finance, and marketing, enabling us to understand the impact of interventions, optimize processes, and predict outcomes accurately.
Conclusion
Understanding causality in machine learning is crucial for developing accurate and reliable models. By considering causal relationships rather than just correlation, we can gain deeper insights into the underlying mechanisms, make better predictions, and take more informed actions. Causal inference methods offer a powerful framework for inferring cause-effect relationships from observational and experimental data, providing a scientific basis for decision making.
However, it is important to be aware of the limitations and challenges that come with causal inference, such as confounding variables and data bias. Despite these challenges, the field of causality in machine learning is rapidly advancing, with new techniques and approaches being developed to tackle complex causal questions.
By incorporating causality into our machine learning workflow, we can unlock new opportunities and enhance the performance of our models in various domains, from healthcare to finance. So, let’s embrace the power of causality and continue pushing the boundaries of machine learning for a better future.
